SELECT
Содержание раздела
- Запрос прошлых состояний данных
- Как запрос выбирает данные
- Статистика
- Синтаксис
- WITH
- FOR SYSTEM_TIME
- Синтаксис
- Поддерживаемые сущности
- FOR SYSTEM_TIME AS OF ‘timestamp’
- FOR SYSTEM_TIME AS OF DELTA_NUM delta_num
- FOR SYSTEM_TIME AS OF LATEST_UNCOMMITTED_DELTA
- FOR SYSTEM_TIME STARTED IN (delta_num1, delta_num2)
- FOR SYSTEM_TIME FINISHED IN (delta_num1, delta_num2)
- FOR SYSTEM_TIME AS OF CN sys_cn
- FOR SYSTEM_TIME STARTED CN (sys_cn1, sys_cn2)
- FOR SYSTEM_TIME FINISHED CN (sys_cn1, sys_cn2)
- FOR SYSTEM_TIME STARTED TS (datetime1, datetime2)
- FOR SYSTEM_TIME FINISHED TS (datetime1, datetime2)
- FOR SYSTEM_TIME RAW
- Способы указания значения FOR SYSTEM_TIME
- Особенности выражений со STARTED и FINISHED
- JOIN
- WHERE
- GROUP BY
- HAVING
- UNION
- INTERSECT
- EXCEPT
- ORDER BY
- LIMIT
- OFFSET
- FETCH
- DATASOURCE_TYPE
- ESTIMATE_ONLY
- Поддерживаемые функции
- LISTAGG
- Функции по управлению числовыми последовательностями
- Функции по управлению текстовым поиском
- CHECK_SUM_MD5
- CHECK_SUM_INT64
- TO_TIMESTAMP_MICROS
- DATE_TRUNC
- Варианты ответа
- Ограничения
- Примеры
- Звездочка и WHERE
- DATASOURCE_TYPE
- GROUP BY, ORDER BY и LIMIT
- SELECT без таблицы
- OFFSET
- ORDER BY, LIMIT и OFFSET
- FOR SYSTEM_TIME AS OF DELTA_NUM
- FOR SYSTEM_TIME AS OF CN
- FOR SYSTEM_TIME STARTED TS
- Соединение таблиц из разных логических БД
- Соединение изменений по выбранным полям
- Запрос изменений дельты из логического представления
- Запрос данных из прокси-таблицы
- Запрос данных из standalone-таблицы
- Соединение standalone-таблицы и логической таблицы
- Запрос данных из партиционированных таблиц
- Запрос данных из партиции
- Запрос данных, включая системные столбцы sys_from и sys_to
- Запрос данных с фильтром по системному столбцу sys_from
- Запрос с именованными параметрами
- Запрос с индексированными параметрами
- Запрос с табличным параметром
- Запросы к сущностям, версионируемым во внешней системе
Поддерживается в версиях: 7.7 / 7.6 / 7.5 / 7.4 / 7.3 / 7.2 / 7.1 / 7.0 / 6.12 / 6.11 / 6.10 / 6.9 / 6.8 / 6.7 / 6.6 / 6.5 / 6.4 / 6.3 / 6.2 / 6.1 / 6.0 / 5.8 / 5.7 / 5.6 / 5.5 / 5.4 / 5.3 / 5.2 / 5.1 / 5.0.
Запрос возвращает данные из следующих сущностей и их соединений:
- логических таблиц,
- прокси-таблиц,
- снапшот-таблиц,
- standalone-таблиц,
- логических представлений,
- материализованных представлений.
Запрос можно использовать:
- для чтения данных;
- для получения информации о самом запросе;
- как подзапрос в следующих запросах:
- на вставку данных из другой сущности,
- на выгрузку данных,
- на создание или обновление логического представления,
- на создание материализованного представления.
Запросы чтения могут балансироваться по датасорсам в зависимости от приоритета, назначенного запросу.
Синтаксис чтения из standalone-таблицы предполагает использование внешней readable-таблицы, которая указывает на нужную standalone-таблицу.
Если нужно выбрать сотни и более записей, используйте потоковое чтение данных или выгрузку данных.
Запрос прошлых состояний данных
По умолчанию SELECT-запросы возвращают текущие данные. Чтобы запросить прошлые состояния данных, используйте FOR SYSTEM_TIME. Для логических таблиц, логических и материализованных представлений можно запросить как состояние на любой момент, так и изменения за период, для снапшот-таблиц — только изменения за период.
FOR SYSTEM_TIME для других сущностей и сценариев не поддерживается: запросы возвращают текущее состояние данных или пустой результат (подробнее см. в секции FOR SYSTEM_TIME).
Как запрос выбирает данные
Запрос к непартиционированным сущностям выбирает их данные из датасорса, указанного в запросе или выбранного системой для исполнения запроса.
Запрос к партиционированной таблице автоматически перенаправляется в задействованные партиции и возвращает объединенную выборку по этим партициям из всех датасорсов, выбранных для исполнения запроса.
Статистика
Запросы SELECT учитываются в категории READ статистики. Подробнее о категориях запросов в статистике см. в разделе GET_ENTITY_STATISTICS, о способах просмотра статистики — в разделе Управление статистикой.
Синтаксис
[ WITH cte_name [(cte_column_name[, ... ])] AS (cte_select) ]
SELECT expression
[ FROM
{ [db_name1.][major_version1.minor_version1.]entity_name1
[FOR SYSTEM_TIME time_expression] | (select1) }
[ [AS] alias1 ]
[ [join_prefix] JOIN
{ [db_name2.][major_version2.minor_version2.]entity_name2
[FOR SYSTEM_TIME time_expression] | (select2) }
[ [AS] alias2 ]
ON join_condition ]
[ WHERE condition ]
[ GROUP BY column_name [, ... ] ]
[ HAVING condition ]
[ {UNION | INTERSECT | EXCEPT} [ALL | DISTINCT] (select3) ]
[ ORDER BY column_name [ASC | DESC] [, ... ] ]
[ LIMIT count ]
[ OFFSET start [ROW | ROWS] ]
[ FETCH {FIRST | NEXT} count ROWS ONLY ]
[ DATASOURCE_TYPE = 'datasource_name' ]
[ ESTIMATE_ONLY [ (estimate_option[, ... ]) ] ]
Ключевые слова имеют ограничения, перечисленные в секции ограничений.
В некоторых выражениях значение должно быть приведено к ожидаемому с помощью CAST. Примеры доступны в разделе Поддержка SQL.
Параметры:
expression-
Выражение для составления результата SELECT-запроса. Может содержать любой из вариантов:
- имена столбцов задействованных сущностей, включая системные столбцы
sys_from,sys_toиsys_op; - символ
*для выбора всех столбцов, кроме системных; - сочетание имен столбцов, констант, операторов и SQL-функций.
- имена столбцов задействованных сущностей, включая системные столбцы
db_name-
Имя логической базы данных, из которой выбираются данные. Опционально, если выбрана логическая БД, используемая по умолчанию. Значения
db_name1иdb_name2могут как совпадать, так и отличаться. major_version.minor_version-
Версия сущности в формате внешней системы, состоящая из двух чисел (например, 5.0). Второе число (
minor_version) не влияет на обработку запросов, но должно быть указано при указании первого.Если версия указана, запрос перенаправляется к сущности
v<major_version>_<entity_name>или, если такой нет, к<entity_name>. Например:marketing.5.0.sales→marketing.v5_salesилиmarketing.sales. entity_name-
Имя таблицы или представления, откуда выбираются данные.
select-
SELECT-подзапрос.
alias-
Псевдоним таблицы или представления. Должен соответствовать соглашениям об именах.
Любые аргументы запроса, кроме имен логических сущностей и их столбцов, могут быть заданы как индексированные, именованные и (или) табличные параметры.
WITH
Задает одно или несколько обобщенных табличных выражений (Common Table Expressions или CTE, далее — табличное выражение), используемых в основном запросе.
Табличные выражения доступны в запросах к ADB и ADP.
Рекурсивные и материализованные табличные выражения не поддерживаются.
Табличные выражения вычисляются перед основным запросом и сохраняются до завершения его исполнения. Используя табличные представления, вы можете упростить сложные запросы, разбив их на более простые части. Как правило, запрос с подзапросами можно переписать с использованием WITH.
В табличных выражениях можно использовать поддерживаемые ключевые слова, в том числе FOR SYSTEM_TIME, а также другие табличные выражения того же запроса. В табличных выражениях не поддерживаются операторы, изменяющие данные: INSERT, UPSERT и DELETE.
Синтаксис:
WITH cte_name [(cte_column_name[, ... ])] AS (cte_select)
Где:
cte_name— имя обобщенного табличного выражения;cte_column_name— имя столбца, выбираемого из подзапросаcte_selectдля создания обобщенного табличного выражения. Если столбцы не указаны, в табличном выражении используются столбцы подзапросаcte_select;cte_select— SELECT-подзапрос, определяющий состав обобщенного табличного выражения.
Пример запроса:
-- запрос данных о продажах в наиболее популярных магазинах с двумя табличными выражениями
WITH sales_by_shops AS (
SELECT store_id, COUNT(id) AS total_sales
FROM marketing.sales
GROUP BY store_id),
top_stores AS (
SELECT store_id
FROM sales_by_shops
WHERE total_sales > 20
)
SELECT store_id,
product_code,
SUM(product_units) AS product_units,
COUNT(id) AS product_sales
FROM marketing.sales
WHERE store_id IN (SELECT store_id FROM top_stores)
GROUP BY store_id, product_code
ORDER BY store_id, product_units
DATASOURCE_TYPE = 'adp'
FOR SYSTEM_TIME
Задает момент времени или период, за который выбираются данные или изменения данных. Относится к логической сущности, после имени которой следует.
Синтаксис см. в секции FOR SYSTEM_TIME > Синтаксис, о поддержке для каждого вида сущности — в секции FOR SYSTEM_TIME > Поддерживаемые сущности.
Если ключевое слово не указано, возвращаются данные, описанные в таблице ниже.
| Тип сущности | Какие данные возвращаются без FOR SYSTEM_TIME |
|---|---|
| Логическая таблица, логическое представление | Текущие данные по состоянию на серверное время |
| Материализованное представление | Текущие данные по состоянию на конец последней завершенной синхронизации представления |
| Снапшот-, прокси-, или standalone-таблица | Текущие данные |
Синтаксис
-- данные по состоянию на указанный момент
FOR SYSTEM_TIME AS OF { 'timestamp' | DELTA_NUM delta_num | LATEST_UNCOMMITTED_DELTA | CN sys_cn }
-- изменения за указанный период
FOR SYSTEM_TIME { {STARTED | FINISHED} IN (delta_num1, delta_num2) |
{STARTED | FINISHED} CN (sys_cn1, sys_cn2) |
{STARTED | FINISHED} TS (datetime1, datetime2)} }
-- физические данные (без логического преобразования)
FOR SYSTEM_TIME RAW
Поддерживаемые сущности
Ключевое слово FOR SYSTEM_TIME доступно в запросах и подзапросах к сущностям:
- логическим таблицам,
- логическим представлениям,
- материализованным представлениям,
- снапшот-таблицам.
Ключевое слово недоступно:
- для прокси- и standalone-таблиц;
- в подзапросах в составе запросов на создание и изменение логических и материализованных представлений (исключение — инкрементальные подзапросы материализованных представлений);
- в запросах и подзапросах к обобщенным табличным выражениям.
В таблице ниже описана доступность выражений FOR SYSTEM_TIME в SELECT-запросах к таблицам и представлениям.
| Выражение | Логические таблицы, мат. представления, простые лог. представления | Обычные лог. представления (не простые) | Снапшот-таблицы | Прокси-, standalone-таблицы |
|---|---|---|---|---|
FOR SYSTEM_TIME AS OF'timestamp' | + | + | Игнорируется | Игнорируется |
FOR SYSTEM_TIME AS OFDELTA_NUM delta_num | + | + | Игнорируется | Игнорируется |
FOR SYSTEM_TIME AS OFLATEST_UNCOMMITTED_DELTA | + | Ошибка | Игнорируется | Игнорируется |
FOR SYSTEM_TIMESTARTED IN(delta_num1, delta_num2) | + | + Кроме:
| + Правая граница — всегда текущий момент | Пустой результат |
FOR SYSTEM_TIMEFINISHED IN(delta_num1, delta_num2) | + | + Кроме:
| + Правая граница — всегда текущий момент | Пустой результат |
FOR SYSTEM_TIME AS OFCN sys_cn | + | Ошибка | Игнорируется | Игнорируется |
FOR SYSTEM_TIMESTARTED CN(sys_cn1, sys_cn2) | + | Ошибка | + Правая граница — всегда текущий момент | Пустой результат |
FOR SYSTEM_TIMEFINISHED CN(sys_cn1, sys_cn2) | + | Ошибка | + Правая граница — всегда текущий момент | Пустой результат |
FOR SYSTEM_TIMESTARTED TS(datetime1, datetime2) | + | + Кроме:
| + Правая граница — всегда текущий момент | Пустой результат |
FOR SYSTEM_TIMEFINISHED TS(datetime1, datetime2) | + | + Кроме:
| + Правая граница — всегда текущий момент | Пустой результат |
FOR SYSTEM_TIMERAW | + | + | + | Игнорируется |
Для логического представления, основанном на данных нескольких логических БД, данные выбираются на общий момент времени или за общий период. Время определяется по той логической БД, которой принадлежит представление.
FOR SYSTEM_TIME AS OF ‘timestamp’
Выражение определяет данные, которые были текущими на момент timestamp. Доступно для логических таблиц, логических и материализованных представлений без ограничений. Игнорируется для снапшот-, прокси- и standalone-таблиц.
В выборку попадают записи по состоянию:
- на последнюю завершенную операции записи в указанный момент — если выражение относится к логической таблице или логическому представлению;
- на последнюю закрытую дельту в указанный момент — если выражение относится к материализованному представлению.
Момент времени указывается в формате YYYY-MM-DD hh:mm:ss[.microseconds].
SELECT * FROM marketing.clients FOR SYSTEM_TIME AS OF '2023-01-01 00:00:00';
SELECT * FROM marketing.clients FOR SYSTEM_TIME AS OF '2023-01-01 00:00:00.134242';
FOR SYSTEM_TIME AS OF DELTA_NUM delta_num
Выражение определяет данные, которые были текущими на момент закрытия дельты с номером delta_num. Доступно для логических таблиц, логических и материализованных представлений без ограничений. Игнорируется для снапшот-, прокси- и standalone-таблиц.
SELECT * FROM marketing.clients FOR SYSTEM_TIME AS OF DELTA_NUM 10
FOR SYSTEM_TIME AS OF LATEST_UNCOMMITTED_DELTA
Выражение определяет текущие данные, включая изменения открытой дельты (но только из непрерывного диапазона завершенных операций записи).
Выражение доступно для логических таблиц, материализованных представлений без ограничений, для логических представлений — с ограничениями. Игнорируется для снапшот-, прокси- и standalone-таблиц.
SELECT * FROM marketing.clients FOR SYSTEM_TIME AS OF LATEST_UNCOMMITTED_DELTA
FOR SYSTEM_TIME STARTED IN (delta_num1, delta_num2)
Выражение определяет новые и обновленные записи за период с закрытия дельты delta_num1 - 1 (исключая границу) до закрытия дельты delta_num2 (включая границу). Другими словами, в выборку попадают записи, которые стали текущими в указанном периоде — в дельтах или вне дельт.
Для снапшот-таблиц указанная правая граница игнорируется и всегда равна текущему моменту.
Выборка содержит разницу в состоянии данных за период без промежуточных изменений. Подробнее см. в секции Особенности выражений со STARTED и FINISHED.
Выражение доступно для логических таблиц, снапшот-таблиц и материализованных представлений без ограничений, для логических представлений — с ограничениями. Для прокси-таблиц и standalone-таблиц возвращается пустой результат.
-- изменения по диапазону дельт
SELECT * FROM marketing.clients FOR SYSTEM_TIME STARTED IN (10, 20);
-- изменения по одной дельте
SELECT * FROM marketing.clients FOR SYSTEM_TIME STARTED IN (10, 10);
FOR SYSTEM_TIME FINISHED IN (delta_num1, delta_num2)
Выражение определяет удаленные записи за период с закрытия дельты delta_num1 - 1 (исключая границу) до закрытия дельты delta_num2 (включая границу). Другими словами, в выборку попадают записи, которые перестали быть текущими из-за удаления в указанном периоде — в дельтах или вне дельт.
Для снапшот-таблиц указанная правая граница игнорируется и всегда равна текущему моменту.
Выборка содержит разницу в состоянии данных за период без промежуточных изменений. Подробнее см. в секции Особенности выражений со STARTED и FINISHED.
Выражение доступно для логических таблиц, снапшот-таблиц и материализованных представлений без ограничений, для логических представлений — с ограничениями. Для прокси-таблиц и standalone-таблиц возвращается пустой результат.
-- изменения по диапазону дельт
SELECT * FROM marketing.clients FOR SYSTEM_TIME FINISHED IN (10, 20);
-- изменения по одной дельте
SELECT * FROM marketing.clients FOR SYSTEM_TIME FINISHED IN (10, 10);
FOR SYSTEM_TIME AS OF CN sys_cn
Выражение определяет текущие данные по состоянию на операцию записи с номером sys_cn. Если операция еще выполняется, результаты выдачи по ней могут быть не согласованы.
Выражение доступно для логических таблиц и материализованных представлений без ограничений, для логических представлений — с ограничениями. Игнорируется для снапшот-, прокси- и standalone-таблиц.
SELECT * FROM marketing.clients FOR SYSTEM_TIME AS OF CN 1744983131164721
FOR SYSTEM_TIME STARTED CN (sys_cn1, sys_cn2)
Выражение определяет новые и обновленные записи за период с операции sys_cn1 по sys_cn2 (включая обе границы). Другими словами, в выборку попадают записи, которые стали текущими в указанном периоде. Если операции еще выполняются, результаты выдачи по ним могут быть не согласованы.
Для снапшот-таблиц указанная правая граница игнорируется и всегда равна текущему моменту.
Выборка содержит разницу в состоянии данных за период без промежуточных изменений. Подробнее см. в секции Особенности выражений со STARTED и FINISHED.
Выражение доступно для логических таблиц, снапшот-таблиц и материализованных представлений без ограничений, для логических представлений — с ограничениями. Для прокси-таблиц и standalone-таблиц возвращается пустой результат.
-- изменения по диапазону операций
SELECT * FROM marketing.clients FOR SYSTEM_TIME STARTED CN (1744983131164721, 1745013131164903);
-- изменения по одной операции
SELECT * FROM marketing.clients FOR SYSTEM_TIME STARTED CN (1744983131164721, 1744983131164721);
FOR SYSTEM_TIME FINISHED CN (sys_cn1, sys_cn2)
Выражение определяет удаленные записи за период с операции sys_cn1 по sys_cn2 (включая обе границы). Другими словами, в выборку попадают записи, которые перестали быть текущими из-за удаления в указанном периоде. Если операции еще выполняются, результаты выдачи по ним могут быть не согласованы.
Для снапшот-таблиц указанная правая граница игнорируется и всегда равна текущему моменту.
Выборка содержит разницу в состоянии данных за период без промежуточных изменений. Подробнее см. в секции Особенности выражений со STARTED и FINISHED.
Выражение доступно для логических таблиц, снапшот-таблиц и материализованных представлений без ограничений, для логических представлений — с ограничениями. Для прокси-таблиц и standalone-таблиц возвращается пустой результат.
-- изменения по диапазону операций
SELECT * FROM marketing.clients FOR SYSTEM_TIME FINISHED CN (1744983131164721, 1745013131164903);
-- изменения по одной операции
SELECT * FROM marketing.clients FOR SYSTEM_TIME FINISHED CN (1744983131164721, 1744983131164721);
FOR SYSTEM_TIME STARTED TS (datetime1, datetime2)
Выражение определяет новые и обновленные записи за период с момента datetime1 по datetime2 (включая обе границы). Другими словами, в выборку попадают записи, которые стали текущими в указанном периоде.
Для снапшот-таблиц указанная правая граница игнорируется и всегда равна текущему моменту.
Выборка содержит разницу в состоянии данных за период без промежуточных изменений. Подробнее см. в секции Особенности выражений со STARTED и FINISHED.
Выражение доступно для логических таблиц, снапшот-таблиц и материализованных представлений без ограничений, для логических представлений — с ограничениями. Для прокси-таблиц и standalone-таблиц возвращается пустой результат.
Время datetime1 и datetime2 можно указать в любом из форматов:
YYYY-MM-DD hh:mm:ss[.microseconds];- Unix-время — целое число микросекунд с 00:00:00 UTC 1 января 1970 года.
-- изменения за период с указанием строковых меток времени
SELECT * FROM marketing.clients FOR SYSTEM_TIME STARTED TS ('2023-04-17 10:00:00.123', '2023-04-30 22:00:00.123');
-- изменения за период с указанием меток времени относительно Unix-эпохи
SELECT * FROM marketing.clients FOR SYSTEM_TIME STARTED TS (1681725600123000, 1682892000123000);
-- изменения за период с указанием меток времени в разных форматах
SELECT * FROM marketing.clients FOR SYSTEM_TIME STARTED TS ('2023-04-17 10:00:00.123', 1682892000123000);
FOR SYSTEM_TIME FINISHED TS (datetime1, datetime2)
Выражение определяет удаленные записи за период с момента datetime1 по datetime2 (включая обе границы). Другими словами, в выборку попадают записи, которые перестали быть текущими из-за удаления в указанном периоде.
Для снапшот-таблиц указанная правая граница игнорируется и всегда равна текущему моменту.
Выборка содержит разницу в состоянии данных за период без промежуточных изменений. Подробнее см. в секции Особенности выражений со STARTED и FINISHED.
Выражение доступно для логических таблиц, снапшот-таблиц и материализованных представлений без ограничений, для логических представлений — с ограничениями. Для прокси-таблиц и standalone-таблиц возвращается пустой результат.
Время datetime1 и datetime2 можно указать в любом из форматов:
YYYY-MM-DD hh:mm:ss[.microseconds];- Unix-время — целое число микросекунд с 00:00:00 UTC 1 января 1970 года.
-- изменения за период с указанием строковых меток времени
SELECT * FROM marketing.clients FOR SYSTEM_TIME FINISHED TS ('2023-04-17 10:00:00.123', '2023-04-30 22:00:00.123');
-- изменения за период с указанием меток времени относительно Unix-эпохи
SELECT * FROM marketing.clients FOR SYSTEM_TIME FINISHED TS (1681725600123000, 1682892000123000);
-- изменения за период с указанием меток времени в разных форматах
SELECT * FROM marketing.clients FOR SYSTEM_TIME FINISHED TS ('2023-04-17 10:00:00.123', 1682892000123000);
FOR SYSTEM_TIME RAW
Выражение определяет записи, содержащиеся в физических таблицах логической сущности.
Доступно для логических таблиц, снапшот-таблиц, логических и материализованных представлений без ограничений. Для прокси-таблиц и standalone-таблиц возвращается текущий набор записей (аналогично запросу без FOR SYSTEM_TIME RAW).
-- количество текущих записей, включая записи по незавершенным операциям записи
SELECT COUNT(*)
FROM marketing.sales FOR SYSTEM_TIME RAW
WHERE sys_to IS NULL
DATASOURCE_TYPE = 'adp';
-- все текущие и исторические записи с диапазоном версий для каждой из них
SELECT *,
to_timestamp_micros(sys_from) AS sys_from_timestamp,
to_timestamp_micros(sys_to) AS sys_to_timestamp, sys_op
FROM marketing.sales FOR SYSTEM_TIME RAW
DATASOURCE_TYPE = 'adp';
-- текущая и все исторические записи с идентификатором 110113
SELECT *,
to_timestamp_micros(sys_from) AS sys_from_timestamp,
to_timestamp_micros(sys_to) AS sys_to_timestamp, sys_op
FROM marketing.sales FOR SYSTEM_TIME RAW
WHERE id = 110113
DATASOURCE_TYPE = 'adp';
Способы указания значения FOR SYSTEM_TIME
Указать значение FOR SYSTEM_TIME в запросе можно любым из способов:
- с помощью константы — например,
FOR SYSTEM_TIME STARTED CN 1745013131164903; - с помощью параметра — например,
FOR SYSTEM_TIME STARTED CN ?илиFOR SYSTEM_TIME STARTED CN :cn_started.
Подробнее об использовании параметров в запросах см. в разделе Параметры запросов.
Особенности выражений со STARTED и FINISHED
Запросы с FOR SYSTEM_TIME STARTED/FINISHED IN/CN/TS возвращают только итоговые изменения за период, а не последовательность изменений. Пример: если у клиента сменился номер телефона в дельтах 3 и 6, запрос по диапазону дельт FOR SYSTEM_TIME STARTED IN (3, 6) вернет только запись с итоговым номером из дельты 6.
JOIN
Соединяет две выборки. Соединение возможно, если есть хотя бы один датасорс, в котором размещены все соединяемые данные.
Синтаксис:
from_item1 [join_prefix] JOIN from_item2 ON join_condition
Где:
from_item— выборка из логической сущности или SELECT-подзапроса;join_prefix— тип соединения из следующих:[INNER] JOIN— внутреннее соединение,NATURAL JOIN— внутреннее соединение по всем столбцам с одинаковыми именами, ключи соединения не указываются,LEFT [OUTER] JOIN— левое внешнее соединение,RIGHT [OUTER] JOIN— правое внешнее соединение,FULL [OUTER] JOIN— полное внешнее соединение,CROSS JOIN— декартово произведение таблиц или представлений, ключи соединения не указываются;
join_condition— условие соединения. Может включать любые общие столбцы соединяемых сущностей, включая системныеsys_from,sys_toиsys_op.
Некоторые типы соединений доступны не во всех СУБД. Например, в запросах к ADG доступно только соединение [INNER] JOIN.
Подробнее о доступных возможностях см. в разделе Поддержка SQL.
Пример запроса:
SELECT
st.id,
st.category,
s.product_code
FROM marketing.stores AS st
INNER JOIN marketing.sales AS s
ON st.id = s.store_id
WHERE
Задает условия выбора данных. В отличие от HAVING, фильтрует данные до применения GROUP BY, а не наоборот.
Условие может включать любые столбцы задействованных сущностей, включая системные sys_from, sys_to и sys_op. Столбцы указываются отдельно или в составе кортежа.
Синтаксис:
WHERE condition
Пример запроса:
SELECT * FROM marketing.sales
WHERE store_id = 123
Сравнение кортежей (ROW)
Условие может содержать кортежи, сравниваемые друг с другом. Каждый кортеж — это список выражений на основе столбцов, констант и (или) функций в круглых скобках. Все кортежи в условии должны иметь одинаковое количество элементов.
Условия с кортежами поддерживаются для ADB и ADP.
При вычислении условия каждый элемент первого кортежа сравнивается с элементами, имеющими тот же порядковый номер в других кортежах. Например, условие WHERE (store_id, product_units) = (123, 4) проверяет, что store_id = 123 и product_units = 4.
Особенности сравнения кортежей:
- результат равен
NULL, если хотя бы одно из сравниваемых значений равноNULL; - сравнение с операторами
<,<=,>,>=,BETWEENиNOT BETWEENработает, как в PostgreSQL, по принципу сортировки строк, и может возвращать разные результаты при разном порядке перечисления элементов в кортежах.
Синтаксис:
-- условие с оператором сравнения
WHERE [ROW] (expression[, ... ]) { = | <> | > | >= | < | <= } [ROW] (expression[, ... ])
-- условие с оператором IN или NOT IN
WHERE [ROW] (expression[, ... ]) { IN | NOT IN } ( [ROW] (expression[, ... ])[, ... ] )
-- условие с оператором BETWEEN или NOT BETWEEN
WHERE [ROW] (expression[, ... ]) { BETWEEN | NOT BETWEEN } [ROW] (expression[, ... ]) AND [ROW] (expression[, ... ])
Примеры запросов:
-- запрос с условием, содержащим столбцы и константы
SELECT * FROM marketing.sales
WHERE ROW (transaction_date, store_id) >= ROW ('2021-01-01 00:00:00.000', 123)
DATASOURCE_TYPE = 'adp';
-- запрос с условием, содержащим столбцы и индексированные параметры (см. cURL-запрос ниже)
SELECT * FROM marketing.sales
WHERE (product_code, store_id) IN ((?, ?), (?, ?), (?, ?), (?, ?))
DATASOURCE_TYPE = 'adp';
-- запрос с условием, содержащим столбцы и именованные параметры (см. cURL-запрос ниже)
SELECT * FROM marketing.sales
WHERE ROW (transaction_date, store_id, product_units)
BETWEEN ROW (:transaction_date_start, :store_id_start, :product_units_start)
AND ROW (:transaction_date_end, :store_id_end, :product_units_end)
DATASOURCE_TYPE = 'adp';
Пример cURL-запроса с индексированными параметрами в кортеже
curl -X 'POST' \
'http://localhost:9090/api/v1/datamarts/marketing/query?format=json' \
-H 'x-request-id: 53ce2008-5de8-477d-92be-8824356a3046' \
-H 'Content-Type: application/json' \
-d '{
"query": "SELECT * FROM sales WHERE (product_code, store_id) IN ((?, ?), (?, ?), (?, ?), (?, ?)) DATASOURCE_TYPE = 'adp'",
"queryId": "9284746",
"params": [
{
"value": "ABC1835",
"type": "STRING"
},
{
"value": 117,
"type": "LONG"
},
{
"value": "ABC1835",
"type": "VARCHAR"
},
{
"value": 120,
"type": "LONG"
},
{
"value": "ABC1212",
"type": "STRING"
},
{
"value": 117,
"type": "LONG"
},
{
"value": "ABC1212",
"type": "STRING"
},
{
"value": 120,
"type": "LONG"
}
]
}'
Пример cURL-запроса с именованными параметрами в кортеже
curl -X 'POST' \
'http://localhost:9090/api/v1/datamarts/marketing/query?format=json' \
-H 'x-request-id: b14168c4-1349-46d7-a08e-7a244e274b02' \
-H 'Content-Type: application/json' \
-d '{
"query": "SELECT * FROM marketing.sales WHERE ROW (transaction_date, store_id, product_units) BETWEEN ROW (:transaction_date_start, :store_id_start, :product_units_start) AND ROW (:transaction_date_end, :store_id_end, :product_units_end) DATASOURCE_TYPE = 'adp';",
"queryId": "928737892",
"params": [
{
"name": "transaction_date_start",
"value": "2020-05-10 13:12:09",
"type": "TIMESTAMP"
},
{
"name": "transaction_date_end",
"value": "2025-05-10 13:12:09",
"type": "TIMESTAMP"
},
{
"name": "store_id_start",
"value": 1,
"type": "LONG"
},
{
"name": "store_id_end",
"value": 500,
"type": "LONG"
},
{
"name": "product_units_start",
"value": 1,
"type": "LONG"
},
{
"name": "product_units_end",
"value": 30,
"type": "LONG"
}
]
}'
Операторы, доступные для партиционированных таблиц
В запросах к партиционированным таблицам условие WHERE может содержать операторы:
>,>=,<,<=,=,IN,BETWEEN,IS TRUE|FALSE|NULL,IS NOT TRUE|FALSE.
GROUP BY
Задает столбцы, по значениям которых группируются возвращаемые строки. Используется в сочетании с агрегационными функциями.
Синтаксис:
GROUP BY column_name [, ... ]
Пример запроса:
SELECT s.store_id, SUM(s.product_units) AS product_amount
FROM marketing.sales AS s
GROUP BY s.store_id
ORDER BY product_amount DESC
HAVING
Задает условие выбора сгруппированных данных. В отличие от WHERE, фильтрует данные после применения GROUP BY, а не наоборот.
Синтаксис:
HAVING condition
Пример запроса:
SELECT s.store_id, SUM(s.product_units) AS product_amount
FROM marketing.sales AS s
HAVING s.store_id > 120
GROUP BY (s.store_id)
ORDER BY product_amount DESC
UNION
Объединяет две выборки. Результат объединения возвращает строки, которые есть хотя бы в одной выборке.
Синтаксис:
(select1) UNION [ALL | DISTINCT] (select2)
Пример запроса:
SELECT * FROM marketing.sales UNION ALL SELECT * FROM marketing_new.sales
INTERSECT
Пересекает две выборки. Результат пересечения возвращает строки, которые есть в обеих выборках.
Синтаксис:
(select1) INTERSECT [ALL | DISTINCT] (select2)
Пример запроса:
SELECT * FROM marketing.sales INTERSECT DISTINCT SELECT * FROM marketing_new.sales
EXCEPT
Вычитает правую выборку из левой. Результат вычитания возвращает строки, которые принадлежат левой выборке, но не правой.
Синтаксис:
(select1) EXCEPT [ALL | DISTINCT] (select2)
Пример запроса:
SELECT * FROM marketing.sales EXCEPT DISTINCT SELECT * FROM marketing_new.sales
ORDER BY
Задает один или несколько столбцов, по значениям которых сортируются возвращаемые строки. Если ASC и DESC не указаны, результаты сортируются в возрастающем порядке (ASC).
Синтаксис:
ORDER BY column_name [ASC | DESC] [, ... ]
Пример запроса:
SELECT * FROM marketing.sales ORDER BY id ASC, store_id DESC
LIMIT
Задает количество возвращаемых строк. Может использоваться самостоятельно или в паре с ключевым словом OFFSET. Результат применения аналогичен результату применения FETCH.
Синтаксис:
LIMIT count
Пример запроса:
SELECT * from marketing.sales LIMIT 20
OFFSET
Пропускает первые несколько строк результата и выбирает только последующие строки. Примеры запросов см. ниже.
Ключевое слово недоступно в запросах к СУБД ADG.
Синтаксис:
[ORDER BY column_name [ASC | DESC] [, ... ]]]
[LIMIT count]
OFFSET start [ ROW | ROWS ]
[FETCH {FIRST | NEXT} count ROWS ONLY]
В качестве значения ключевого слова можно указать любое неотрицательное целое число, начиная с нуля, или переменную. Если для OFFSET указано значение 0, то пропускается 0 строк, что равносильно запросу без OFFSET.
Запросы с OFFSET без ограничения количества строк не поддерживаются. То есть, если ключевое слово OFFSET указано в запросе, то перед ним должно быть ключевое слово LIMIT или после него должно быть ключевое слово FETCH... ROWS ONLY. Обратного ограничения нет: ключевые слова LIMIT и FETCH... ROWS ONLY можно использовать и без OFFSET.
Рекомендуется сочетать OFFSET с ключевым словом ORDER BY для получения упорядоченного набора строк. Ключевое слово ORDER BY необязательно, однако без него запрос с OFFSET возвращает неупорядоченный и потому непредсказуемый набор строк.
Пример запроса:
-- запрос 20 строк, начиная с десятой, с сортировкой по id
SELECT * from marketing.sales ORDER BY id OFFSET 9 FETCH NEXT 20 ROWS ONLY
FETCH
Задает количество возвращаемых строк. Может использоваться самостоятельно или в паре с ключевым словом OFFSET. Результат применения аналогичен результату применения LIMIT.
Синтаксис:
FETCH {FIRST | NEXT} count ROWS ONLY
Пример запроса:
SELECT * from marketing.sales FETCH NEXT 20 ROWS ONLY
DATASOURCE_TYPE
Задает имя датасорса, из которого выбираются данные. Поддерживается для логических и снапшот-таблиц, а также логических и материализованных представлений. Регистр букв в имени не учитывается.
Синтаксис:
DATASOURCE_TYPE = 'datasource_name'
Пример запроса:
SELECT sold.store_id, sold.product_amount
FROM marketing.stores_by_sold_products AS sold
DATASOURCE_TYPE = 'adqm'
В запросе к партиционированной таблице ключевое слово DATASOURCE_TYPE применяется к партициям, затронутых запросом, а не к самой таблице. Указанный датасорс должен быть общим для всех таких партиций, иначе возвращается ошибка.
Если ключевое слово не указано, система определяет наиболее оптимальный датасорс для исполнения запроса.
ESTIMATE_ONLY
Позволяет запросить информацию о выполнении запроса к данным, а не сами данные.
Синтаксис:
ESTIMATE_ONLY [ (estimate_option[, ... ]) ]
Где estimate_option — опция команды EXPLAIN в СУБД ADB и ADP, кроме FORMAT (формат — всегда JSON).
Список доступных опций и их сочетаний для ADP см. в документации PostgreSQL, для ADB — в документации Greenplum.
Примеры запросов:
-- ESTIMATE_ONLY без дополнительных опций
SELECT s.store_id, SUM(s.product_units) AS product_amount
FROM marketing.sales AS s
GROUP BY (s.store_id)
ORDER BY product_amount DESC
ESTIMATE_ONLY;
-- ESTIMATE_ONLY c опцией ANALYZE
SELECT * FROM marketing.sales
DATASOURCE_TYPE = 'ADP'
ESTIMATE_ONLY(ANALYZE);
-- ESTIMATE_ONLY c опциями ANALYZE, WAL и TIMING
SELECT * FROM marketing.sales
DATASOURCE_TYPE = 'ADP'
estimate_only(ANALYZE, WAL TRUE, TIMING FALSE);
Формат ответа
Запрос с ESTIMATE_ONLY возвращает объект ResultSet с JSON-строкой следующего формата (для партиционированных таблиц может вернуться несколько строк, по одной на каждый задействованный в запросе датасорс):
{
"datasource": "<имя_датасорса>",
"estimation": "<план_выполнения_запроса>",
"query": "<обогащенный_запрос>"
}
Где:
имя_датасорса— имя датасорса, в котором предполагается выполнение запроса;- (ADB, ADP)
план_выполнения_запроса— результат выполнения командыEXPLAINв датасорсе; подробнее см. в документации PostgreSQL и Greenplum; обогащенный_запрос— запрос, подготовленный системой на основе исходного запроса с учетом специфики типа датасорса.
Начиная с версии 6.1, система возвращает обогащенный запрос с символами переноса строки \n. В предыдущих версиях обогащенный запрос возвращался без этих символов.
Пример ответа из ADB
Ниже показан пример JSON-строки, полученной из датасорса типа ADB по запросу с ESTIMATE_ONLY без дополнительных опций. Для наглядности пример представлен в виде дерева, а не плоской строки.
{
"datasource":"ADB",
"estimation":[
{
"Plan":{
"Node Type":"Gather Motion",
"Senders":4,
"Receivers":1,
"Slice":1,
"Segments":4,
"Gang Type":"primary reader",
"Startup Cost":0.0,
"Total Cost":6.0,
"Plan Rows":5,
"Plan Width":88,
"Plans":[
{
"Node Type":"Result",
"Parent Relationship":"Outer",
"Slice":1,
"Segments":4,
"Gang Type":"primary reader",
"Startup Cost":0.0,
"Total Cost":6.0,
"Plan Rows":5,
"Plan Width":88,
"Plans":[
{
"Node Type":"Index Scan",
"Parent Relationship":"Outer",
"Slice":1,
"Segments":4,
"Gang Type":"primary reader",
"Scan Direction":"Forward",
"Index Name":"sales_actual_sys_from_idx",
"Relation Name":"sales_actual",
"Alias":"sales_actual",
"Startup Cost":0.0,
"Total Cost":6.0,
"Plan Rows":5,
"Plan Width":88,
"Index Cond":"(sys_from <= '1745568932641134'::bigint)",
"Filter":"(COALESCE(sys_to, '9223372036854775807'::bigint) >= '1745568932641134'::bigint)"
}
]
}
]
},
"Settings":{
"Optimizer":"Pivotal Optimizer (GPORCA)"
}
}
],
"query":"SELECT id, transaction_date, product_code, product_units, store_id, description\nFROM marketing.sales_actual\nWHERE sys_from <= 1745568932641134 AND COALESCE(sys_to, 9223372036854775807) >= 1745568932641134"
}
Пример ответа из ADP
Ниже показан пример JSON-строки, полученной из датасорса типа ADP по запросу с ESTIMATE_ONLY без дополнительных опций. Для наглядности пример представлен в виде дерева, а не плоской строки.
{
"datasource":"ADP",
"estimation":[
{
"Plan":{
"Node Type":"Seq Scan",
"Parallel Aware":false,
"Async Capable":false,
"Relation Name":"sales_actual",
"Alias":"sales_actual",
"Startup Cost":0.0,
"Total Cost":1.14,
"Plan Rows":1,
"Plan Width":1064,
"Filter":"((sys_from <= '1745568932641134'::bigint) AND (COALESCE(sys_to, '9223372036854775807'::bigint) >= '1745568932641134'::bigint))"
}
}
],
"query":"SELECT id, transaction_date, product_code, product_units, store_id, description\nFROM marketing.sales_actual\nWHERE sys_from <= 1745568932641134 AND COALESCE(sys_to, 9223372036854775807) >= 1745568932641134"
}
Поддерживаемые функции
В запросе можно использовать все функции, отмеченные как поддерживаемые в разделе Поддержка SQL.
В этом разделе рассмотрены следующие функции:
- LISTAGG,
- функции по управлению числовыми последовательностями,
- функции по управлению текстовым поиском,
- функции по управлению контрольными суммами:
- TO_TIMESTAMP_MICROS.
LISTAGG
Функция объединяет значения в одну строку, перечисляя их через заданный разделитель. После последнего значения разделитель не добавляется. Строки со значением NULL пропускаются, и соответствующий разделитель не добавляется.
По умолчанию результаты не сортируются, для их сортировки укажите условие сортировки.
Функция доступна в запросах к СУБД ADB и ADP. Подробнее см. в разделе Поддержка SQL.
Синтаксис:
LISTAGG (expression, separator)
[WITHIN GROUP (ORDER BY order_by_expression_list [ ASC | DESC ])]
Где:
expression— выражение для выбора значений. Может иметь любой тип данных; перед объединением значений система приводит их к типуVARCHAR;separator— разделитель между значениями. Может быть любым выражением, кроме символа перевода строки;order_by_expression_list— выражение для сортировки результатов. По умолчанию результаты сортируются в порядке ASC (по возрастанию).
Примеры запросов:
-- запрос плоского списка ФИО клиентов с их датой рождения
SELECT
LISTAGG (last_name || ' ' || first_name || ' ' || patronymic_name || ' ' || birth_date , ', ')
WITHIN GROUP (ORDER BY last_name, first_name, patronymic_name DESC) as client_info
FROM marketing.clients datasource_type = 'adp';
|client_info |
|------------------------------------------------------------------------|
|Васильева Мария Ивановна 1985-01-10, Сидоров Василий Петрович 1980-12-26|
-- запрос списка адресов магазинов с группировкой по городам
SELECT region, LISTAGG (address, '; ') WITHIN GROUP (ORDER BY address) as addresses_by_city
FROM marketing.stores
GROUP BY region
ORDER BY region ASC
DATASOURCE_TYPE = 'adb';
|region |addresses_by_city |
|---------------+------------------------------------|
|Калуга |пер. Достоевского, 12; ул. Новая, 73|
|Москва |ул. Красная, 15; ул. Цветочная, 33/1|
|Нижний Новгород|пр. Ветеранов, 125; пр. Ленина, 1 |
Функции по управлению числовыми последовательностями
Система поддерживает следующие функции по управлению числовыми последовательностями, доступные в запросах к СУБД ADB и ADP:
Система позволяет управлять числовыми последовательностями с помощью команд и функций, но сами последовательности создаются и хранятся в СУБД. Подробнее о числовых последовательностях см. в документации PostgreSQL и Greenplum.
NEXTVAL
Переводит текущее значение последовательности на следующее и возвращает результат.
Синтаксис:
NEXTVAL('[schema_name.]sequence_name')
Где:
schema_name— имя схемы СУБД, которой принадлежит числовая последовательность. Если не указано, используется схема СУБД по умолчанию;sequence_name— имя числовой последовательности. Список числовых последовательностей можно получить, выполнив запрос GET_SEQUENCES.
Пример запроса:
SELECT nextval('marketing.counter_by_10') DATASOURCE_TYPE = 'adp2'
Дополнительные примеры использования функции см. в разделе Поддержка SQL.
SETVAL
Переводит текущее значение последовательности на указанное и возвращает результат.
Синтаксис:
SETVAL('[schema_name.]sequence_name', set_value[, is_called])
Где:
schema_name— имя схемы СУБД, которой принадлежит числовая последовательность. Если не указано, используется схема СУБД по умолчанию;sequence_name— имя числовой последовательности. Список числовых последовательностей можно получить, выполнив запрос GET_SEQUENCES;set_value— устанавливаемое значение последовательности;is_called— флаг, который определяет, вернется ли устанавливаемое значение при следующем вызове функцииNEXTVALпослеSETVAL. Возможные значения:true(по умолчанию) — устанавливаемое значение считается уже использованным, и вызовNEXTVALвернет значение, следующее за установленным;false— устанавливаемое значение вернется при вызовеNEXTVAL.
Пример запроса:
SELECT setval('asc_counter_increased_by_1', 201) DATASOURCE_TYPE = 'adp2'
Дополнительные примеры использования функции см. в разделе Поддержка SQL.
CURRVAL
Возвращает:
- текущее значение последовательности, выданное при последнем вызове функции
NEXTVALилиSETVAL(что было последним); - значение
NULL, если для последовательности ни разу не вызывались функцииNEXTVALиSETVAL.
В отличие от одноименной функции в PostgreSQL, функция возвращает последнее выданное значение последовательности независимо от того, в какой сессии (текущей или нет) оно было выдано.
Синтаксис:
CURRVAL('[schema_name.]sequence_name')
Где:
schema_name— имя схемы СУБД, которой принадлежит числовая последовательность. Если не указано, используется схема СУБД по умолчанию;sequence_name— имя числовой последовательности. Список числовых последовательностей можно получить, выполнив запрос GET_SEQUENCES.
Пример запроса:
SELECT currval('asc_counter_increased_by_1') DATASOURCE_TYPE = 'adp2'
Дополнительные примеры использования функции см. в разделе Поддержка SQL.
Функции по управлению текстовым поиском
Система поддерживает следующие функции по управлению текстовым поиском:
Поддерживаемые варианты сравнений текстовых значений в запросах:
tsvector @@ tsquery,tsquery @@ tsvector,text @@ tsquery.
Система поддерживает функции текстового поиска, но сам поиск выполняется в СУБД. Подробнее о текстовом поиске см. в документации PostgreSQL и Greenplum.
Функции по управлению текстовым поиском подготавливают текстовые значения, указанные как аргументы этих функций, для сравнения с другими текстовыми значениями (подготовленными или нет). Подготовка текстовых значений к текстовому поиску зависит от выбранной конфигурации текстового поиска и заключается в превращении текста в список лексем.
Скорость выполнения запросов с функциями текстового поиска в СУБД ADP можно увеличить, создав индекс типа GIN или GIST для тех столбцов таблиц, которые будут участвовать в текстовом поиске. Например: CREATE INDEX fts_idx_for_sales ON marketing.sales_actual USING gin (to_tsvector('russian', description)).
Конфигурацию текстового поиска можно задать как аргумент функции или использовать конфигурацию по умолчанию. Список доступных конфигураций доступен с помощью прямого запроса к СУБД: SELECT * FROM pg_catalog.pg_ts_config.
TO_TSVECTOR
Подготавливает текстовые значения, выбранные запросом, для сравнения с другим текстом. Возвращает список лексем с их позицией в тексте.
Функция доступна в запросах к СУБД ADB и ADP.
Синтаксис:
TO_TSVECTOR([search_config,] varchar_column)
Где:
search_config— конфигурация текстового поиска. Список доступных конфигураций можно получить, выполнив прямой запрос к СУБД:SELECT * FROM pg_catalog.pg_ts_config;varchar_column— имя столбца, содержащего текстовое значение. Можно указать имена нескольких столбцов, соединенных функциейCOALESCE.
Примеры использования функции см. ниже и в разделе Поддержка SQL.
TO_TSQUERY
Подготавливает слова, указанные как аргумент функции, для сравнения с другим текстом. Возвращает список лексем, соединенных оператором & (AND).
Если в качестве аргумента указано несколько слов, они должны быть соединены любыми из следующих операторов: & (AND), | (OR), ! (NOT), и (или) <-> (FOLLOWED BY).
Функция доступна в запросах к СУБД ADB и ADP.
Синтаксис:
TO_TSQUERY([search_config,] formatted_text)
Где:
search_config— конфигурация текстового поиска. Список доступных конфигураций можно получить, выполнив прямой запрос к СУБД:SELECT * FROM pg_catalog.pg_ts_config;formatted_text— текст, состоящий из слов и операторов.
Пример запроса:
SELECT * FROM marketing.sales
WHERE to_tsvector('russian', description) @@ to_tsquery('russian', 'акция & (лето | зима)')
DATASOURCE_TYPE = 'adp';
|id| transaction_date |product_code|product_units|store_id|description |
|--+-----------------------+------------+-------------+--------+---------------------------|
|13|2023-07-22 13:17:47.000|ABC0002 |4 |123 |Покупка по акции яркое лето|
|12|2023-07-23 20:05:56.000|ABC0001 |6 |234 |Акция "Яркое лето" |
|14|2023-07-23 09:34:10.000|ABC0003 |3 |123 |Акция Лето |
|15|2023-10-15 10:11:01.000|ABC0003 |1 |123 |Акция "Уютная зима" |
Дополнительные примеры использования функции см. в разделе Поддержка SQL.
PLAINTO_TSQUERY
Подготавливает неформатированный текст, указанный как аргумент функции, для сравнения с другим текстом. Возвращает список лексем, соединенных оператором & (AND).
Функция доступна в запросах к СУБД ADB и ADP.
Синтаксис:
PLAINTO_TSQUERY([search_config,] unformatted_text)
Где:
search_config— конфигурация текстового поиска. Список доступных конфигураций можно получить, выполнив прямой запрос к СУБД:SELECT * FROM pg_catalog.pg_ts_config;unformatted_text— неформатированный текст, без указания операторов.
Пример запроса:
SELECT * FROM marketing.sales
WHERE to_tsvector('russian', description) @@ plainto_tsquery('russian', 'акция лето')
DATASOURCE_TYPE = 'adp';
|id|transaction_date |product_code|product_units|store_id|description |
|--+-----------------------+------------+-------------+--------+---------------------------|
|13|2023-07-22 13:17:47.000|ABC0002 |4 |123 |Покупка по акции яркое лето|
|12|2023-07-23 20:05:56.000|ABC0001 |6 |234 |Акция "Яркое лето" |
|14|2023-07-23 09:34:10.000|ABC0003 |3 |123 |Акция Лето |
Дополнительные примеры использования функции см. в разделе Поддержка SQL.
PHRASETO_TSQUERY
Подготавливает неформатированный текст, указанный как аргумент функции, для сравнения с другим текстом, с сохранением порядка слов. Возвращает список лексем, соединенных оператором <-> (FOLLOWED BY).
Функция доступна в запросах к СУБД ADP.
Синтаксис:
PHRASETO_TSQUERY([search_config,] unformatted_text)
Где:
search_config— конфигурация текстового поиска. Список доступных конфигураций можно получить, выполнив прямой запрос к СУБД:SELECT * FROM pg_catalog.pg_ts_config;unformatted_text— неформатированный текст, без указания операторов.
Пример запроса:
SELECT * FROM marketing.sales
WHERE to_tsvector('russian', description) @@ phraseto_tsquery('russian', 'яркое лето')
DATASOURCE_TYPE = 'adp';
|id|transaction_date |product_code|product_units|store_id|description |
|--+-----------------------+------------+-------------+--------+---------------------------|
|13|2023-07-22 13:17:47.000|ABC0002 |4 |123 |Покупка по акции яркое лето|
|25|2023-08-23 20:05:56.000|ABC1111 |6 |234 |Покупка по яркому лету |
|12|2023-07-23 20:05:56.000|ABC0001 |6 |234 |Акция "Яркое лето" |
Дополнительные примеры использования функции см. в разделе Поддержка SQL.
WEBSEARCH_TO_TSQUERY
Подготавливает неформатированный текст, указанный как аргумент функции, для сравнения с другим текстом, с сохранением порядка слов. Возвращает список лексем, соединенных операторами & (AND), | (OR), ! (NOT), и <-> (FOLLOWED BY).
В отличие от PLAINTO_TSQUERY и PHRASETO_TSQUERY, функция поддерживает операторы OR и - (NOT), а также включение слов с сохранением их порядка или без него.
Функция доступна в запросах к СУБД ADP.
Синтаксис:
WEBSEARCH_TO_TSQUERY([search_config,] unformatted_text)
Где:
search_config— конфигурация текстового поиска. Список доступных конфигураций можно получить, выполнив прямой запрос к СУБД:SELECT * FROM pg_catalog.pg_ts_config;unformatted_text— неформатированный текст. Может содержать операторыORи-(NOT) и двойные кавычки для обрамления фразы, в которой должен быть сохранен порядок слов.
Пример запроса:
SELECT * FROM marketing.sales
WHERE to_tsvector('russian', description)
@@ websearch_to_tsquery('russian', 'зима OR лето -яркое')
DATASOURCE_TYPE = 'adp';
|id|transaction_date |product_code|product_units|store_id|description |
|--+-----------------------+------------+-------------+--------+-------------------|
|14|2023-07-23 09:34:10.000|ABC0003 |3 |123 |Акция Лето |
|15|2023-10-15 10:11:01.000|ABC0003 |1 |123 |Акция "Уютная зима"|
Дополнительные примеры использования функции см. в разделе Поддержка SQL.
CHECK_SUM_MD5
Рассчитывает контрольную сумму в шестнадцатеричном формате (MD5) для указанного выражения.
Функция доступна в запросах к СУБД ADP и ADB.
Для повышения производительности вместо констант (литералов) в функции рекомендуется использовать параметры или значения из SELECT-подзапроса.
Синтаксис
CHECK_SUM_MD5([ROW](expression[, ... ]))
Где:
expression— выражение для выбора значений. Может иметь любой тип данных из поддерживаемых.
Функция учитывает регистр в строковых выражениях. Например, результат SELECT CHECK_SUM_MD5('ABC') отличается от SELECT CHECK_SUM_MD5('abc').
Пример с контрольными суммами по столбцу и строке
SELECT
CHECK_SUM_MD5(id) AS id_column_md5,
CHECK_SUM_MD5(
ROW(id, transaction_date, product_code, product_units, store_id, description)
) AS row_md5,
sys_from
FROM marketing.sales
Пример вывода:
|id_column_md5 |row_md5 |sys_from |
|--------------------------------|--------------------------------|----------------|
|b47daa8ef89c9bf9e36c0b4fb2473fe2|e4c3d75d335e87a6f824fabe54478110|1753193414693558|
|a2633823d36dee8084721be1ca90182b|33461dc8f40dada08163929a272ef622|1753193472209548|
Расчет контрольной суммы во внешней СУБД
Рассчитать контрольную сумму во внешней СУБД PostgreSQL или Greenplum, находящейся вне хранилища (например, для сравнения результата с Prostore), можно с помощью SELECT с выражением из таблицы ниже.
| Контрольная сумма | Расчет во внешней СУБД | Расчет в Prostore |
|---|---|---|
| По одному выражению в каждой строке | MD5(CAST(expr AS VARCHAR)) | CHECK_SUM_MD5(expr) |
| По кортежу выражений в каждой строке | MD5(CAST((expr1, expr2, ... ) AS VARCHAR)) | CHECK_SUM_MD5(ROW(expr1, expr2, ... )) |
Примеры запросов с расчетом контрольной суммы в каждой строке по кортежу, включающему все столбцы таблицы:
-- запрос во внешней СУБД
SELECT MD5(CAST(
(id,
transaction_date,
product_code,
product_units,
store_id,
description)
AS VARCHAR)) AS row_md5
FROM marketing_ext_db.sales;
-- запрос в Prostore
SELECT CHECK_SUM_MD5(
ROW
(id,
transaction_date,
product_code,
product_units,
store_id,
description)
) AS row_md5
FROM marketing.sales;
CHECK_SUM_INT64
Рассчитывает 64-битную контрольную сумму для указанного выражения.
Функция доступна в запросах к СУБД ADP и ADB.
Для повышения производительности вместо констант (литералов) в функции рекомендуется использовать параметры или значения из SELECT-подзапроса.
Контрольную сумму по всей сущности можно получить, просуммировав контрольные суммы всех ее строк (см. пример ниже).
Синтаксис
CHECK_SUM_INT64([ROW](expression[, ... ]))
Где:
expression— выражение для выбора значений. Может иметь любой тип данных из поддерживаемых.
Функция учитывает регистр в строковых выражениях. Например, результат SELECT CHECK_SUM_INT64('ABC') отличается от SELECT CHECK_SUM_INT64('abc').
Пример с контрольными суммами по столбцу и строке
SELECT
CHECK_SUM_INT64(id) AS id_column_int64,
CHECK_SUM_INT64(
ROW(id, transaction_date, product_code, product_units, store_id, description)
) AS row_int64,
sys_from
FROM marketing.sales
Пример вывода:
|id_column_int64 |row_int64 |sys_from |
|--------------------|--------------------|----------------|
|-5441005243760600071|-1962488217309640794|1753193414693558|
|-6745486090348663168|3694673293229272480 |1753193472209548|
Пример с контрольной суммой по таблице в дельте
SELECT CAST(SUM(CHECK_SUM_INT64(
ROW(id, transaction_date, product_code, product_units, store_id, description)
)) AS VARCHAR) AS table_int64
FROM marketing.sales
FOR SYSTEM_TIME AS OF DELTA_NUM 2
Пример вывода:
|table_int64 |
|-------------------|
|2651730711729099024|
Пример с контрольной суммой по таблице с условием
SELECT CAST(SUM(CHECK_SUM_INT64(
ROW(id, transaction_date, product_code, product_units, store_id, description)
)) AS VARCHAR) AS table_int64
FROM marketing.sales
WHERE transaction_date BETWEEN '2021-01-01 00:00:00.000000' AND '2021-07-31 23:59:59.999999'
Пример вывода:
|table_int64 |
|---------------------|
|-16745719123427502634|
Расчет контрольной суммы во внешней СУБД
Рассчитать контрольную сумму во внешней СУБД PostgreSQL или Greenplum, находящейся вне хранилища (например, для сравнения результата с Prostore), можно с помощью SELECT с выражением из таблицы ниже.
Контрольная сумма в Prostore ограничена типом BIGINT. Чтобы избежать переполнения при расчете по множеству строк вместе, используйте любой из последних трех способов в таблице.
| Контрольная сумма | Расчет во внешней СУБД | Расчет в Prostore |
|---|---|---|
| По одному выражению в каждой строке | CAST(CAST(('x' || MD5(CAST(expr AS VARCHAR))) AS BIT(64)) AS BIGINT) | CHECK_SUM_INT64(expr) |
| По кортежу выражений в каждой строке | CAST(CAST(('x' || MD5(CAST((expr1, expr2, ... ) AS VARCHAR))) AS BIT(64)) AS BIGINT) | CHECK_SUM_INT64(ROW(expr1, expr2, ... ) |
| По кортежу выражений во всех строках (с суммой по строкам и приведением к VARCHAR) | CAST(SUM(CAST(CAST(('x' || MD5(CAST((expr1, expr2, ... ) AS VARCHAR))) AS BIT(64)) AS BIGINT)) AS VARCHAR) | CAST(SUM(CHECK_SUM_INT64(ROW(expr1, expr2, ... ))) AS VARCHAR) |
| По кортежу выражений во всех строках (c суммой по строкам и делением на размерность BIGINT) | MOD(SUM(CAST(CAST(('x' || MD5(CAST((expr1, expr2, ... ) AS VARCHAR))) AS BIT(64)) AS BIGINT)), 9223372036854775807) | MOD(SUM(CHECK_SUM_INT64(ROW(expr1, expr2, ... ))), 9223372036854775807) |
| По кортежу выражений во всех строках (cо средним по строкам) | CAST(AVG(CAST(CAST(('x' || MD5(CAST((expr1, expr2, ... ) AS VARCHAR))) AS BIT(64)) AS BIGINT)) AS VARCHAR) | CAST(AVG(CHECK_SUM_INT64(ROW(expr1, expr2, ... ))) AS VARCHAR) |
Примеры запросов с расчетом контрольной суммы по всей таблице (с приведением итога к VARCHAR):
-- запрос во внешней СУБД
SELECT
CAST(SUM(
CAST(CAST(
('x' || MD5(CAST(
(id,
transaction_date,
product_code,
product_units,
store_id,
description)
AS VARCHAR)))
AS BIT(64)) AS BIGINT))
AS VARCHAR) AS table_int64
FROM marketing_ext_db.sales;
-- запрос в Prostore
SELECT
CAST(SUM(
CHECK_SUM_INT64(
ROW
(id,
transaction_date,
product_code,
product_units,
store_id,
description)
)) AS VARCHAR) AS table_int64
FROM marketing.sales;
TO_TIMESTAMP_MICROS
Функция преобразует метку времени из Unix-формата в UTC с сохранением микросекундной точности (YYYY-MM-DD hh:mm:ss.SSSSSS).
Функция доступна в запросах к СУБД ADB и ADP.
Синтаксис:
TO_TIMESTAMP_MICROS(unix_time_in_microseconds)
Где:
unix_time_in_microseconds— выражение, содержащее Unix-метку времени в микросекундах.
Пример запроса:
SELECT id, store_id, sys_from, TO_TIMESTAMP_MICROS(sys_from) AS sys_from_timestamp
FROM marketing.sales
DATASOURCE_TYPE = 'adp';
|id |store_id|sys_from |sys_from_timestamp |
|-------+--------+---------------------+--------------------------|
|710,012|234 |1,745,480,682,074,702|2025-04-24 10:44:42.074702|
|910,011|123 |1,745,480,695,345,943|2025-04-24 10:44:55.345943|
|110,016|123 |1,745,568,932,641,134|2025-04-25 11:15:32.641134|
DATE_TRUNC
Функция усекает значение типа TIMESTAMP, DATE или TIME до заданной точности, обнуляя более мелкие единицы измерения. Например, усечение даты и времени до часов оставляет дату и часы, а минуты и секунды обнуляет.
Функция доступна в запросах к СУБД ADP, ADB и ADQM. Поддерживаемые варианты использования см. в разделе Поддержка SQL.
Синтаксис:
DATE_TRUNC(precision, expression)
Где:
precision— точность, до которой усекается значение выражения. Возможные значения:MICROSECOND,MILLISECOND,SECOND,MINUTE,HOUR,DAY,WEEK,MONTH,QUARTER,YEAR,DECADE,CENTURY,MILLENNIUM;
expression— выражение с типом данныхTIMESTAMP,DATEилиTIME.
Возможные комбинации точности и выражений см. в разделе Поддержка SQL.
Примеры запросов:
-- усечение метки времени в transaction_date до даты
SELECT id, DATE_TRUNC(DAY, transaction_date) as transaction_day FROM marketing.sales
DATASOURCE_TYPE = 'adp';
|id |transaction_date |transaction_day |
|---+--------------------------+--------------------------|
|100|2024-11-30 05:52:47.000000|2024-11-30 00:00:00.000000|
|101|2024-01-21 07:16:18.000000|2024-01-21 00:00:00.000000|
|103|2024-06-12 07:19:38.000000|2024-06-12 00:00:00.000000|
-- выбор транзакций за прошлый месяц
SELECT * FROM marketing.sales
WHERE transaction_date >= DATE_TRUNC(MONTH, TIMESTAMPADD(MONTH, -1, current_date))
AND transaction_date < DATE_TRUNC(MONTH, current_date)
DATASOURCE_TYPE = 'adp2';
|id |transaction_date |product_code|product_units|store_id|description|
|---+--------------------------+------------+-------------+--------+-----------|
|900|2025-12-02 09:11:58.000000|ABC001 |1 |123 | |
|901|2025-12-17 16:49:11.000000|ABC001 |2 |234 | |
Варианты ответа
В ответе возвращается:
- объект ResultSet c выбранными записями или информацией о запросе при успешном выполнении запроса;
- исключение при неуспешном выполнении запроса.
Ограничения
Ограничения сущностей
- В запросе можно обращаться либо к логической БД, либо к сервисной БД (см. SELECT FROM INFORMATION_SCHEMA), но не к обеим одновременно.
- Не поддерживаются запросы к материализованным представлениям с ключевыми словами
FOR SYSTEM_TIME+DATASOURCE_TYPE, если в представлении отсутствуют данные за момент времени, указанный с помощьюFOR SYSTEM_TIME. - Не поддерживаются запросы к внешним readable-таблицам, связанным с топиками Kafka.
Ограничения FOR SYSTEM_TIME
- Не поддерживается:
- в SELECT-запросах и подзапросах к обобщенным табличным выражениям;
- в SELECT-запросах в составе CREATE VIEW, ALTER VIEW и CREATE MATERIALIZED VIEW (кроме инкрементальных подзапросов материализованных представлений).
- Снапшот-таблицы:
FOR SYSTEM_TIME AS OF ...игнорируется;- правая граница в
FOR SYSTEM_TIME STARTED/FINISHED IN/CN/TSигнорируется (всегда равна текущему моменту);
- Прокси- и standalone-таблицы:
FOR SYSTEM_TIME STARTED/FINISHED IN/CN/TSвсегда выбирают 0 записей;FOR SYSTEM_TIME AS OF ...иFOR SYSTEM_TIME RAWигнорируются.
- Обычные логические представления:
- не поддерживают
FOR SYSTEM_TIME AS OF LATEST_UNCOMMITTED_DELTA/CNиFOR SYSTEM_TIME STARTED/FINISHED CN; - не поддерживают
STARTED/FINISHED IN/TS, если их подзапрос содержитORDER BYили обращается к снапшот-таблицам или данным ADQM.
- не поддерживают
Ограничения других ключевых слов
ESTIMATE_ONLYвозвращает план выполнения запроса только для СУБД ADB и ADP.OFFSETне поддерживается без ограничения количества строк.ORDER BYне поддерживается в CREATE MATERIALIZED VIEW.WITH:- Поддерживается только для СУБД ADB и ADP.
- Не поддерживает рекурсивные и материализованные табличные выражения.
- Не поддерживает
DATASOURCE_TYPEи операторы, изменяющие данные (INSERT,UPSERTиDELETE).
Ограничения соединений
- Не поддерживается соединение сущностей, данные которых размещены в разных датасорсах без какого-либо общего датасорса.
- Если ключами соединения в запросе выступают поля типа Nullable, то строки, где хотя бы один из ключей имеет значение
NULL, не соединяются.
Ограничения партиционирования
- JOIN-соединение партиционированных таблиц между собой и с другими данными возможно только в пределах единого датасорса.
Другие ограничения
- Запрос без
FOR SYSTEM_TIMEигнорирует данные с метками времени, превышающими текущее время сервера. - Псевдонимы (алиасы) сущностей и столбцов должны удовлетворять соглашениям об именах.
- При обработке запроса отключенные (отключенный датасорс: Датасорс, отключенный системой из-за сбоя или администратором
) датасорсы (датасорс: СУБД или кластер СУБД хранилища
) пропускаются без возврата ошибки. Ошибка возвращается, если не осталось включенных (включенный датасорс: Датасорс, работающий в штатном режиме
) датасорсов, подходящих для исполнения запроса.
Примеры
Звездочка и WHERE
Запрос с неявным указанием столбцов и ключевым словом WHERE:
SELECT * FROM marketing.sales_snapshot
WHERE store_id = 123
DATASOURCE_TYPE
Запрос с перечислением столбцов и выбором данных из определенного датасорса:
SELECT sold.store_id, sold.product_amount
FROM marketing.stores_by_sold_products AS sold
DATASOURCE_TYPE = 'adqm'
GROUP BY, ORDER BY и LIMIT
Запрос с агрегацией, группировкой и сортировкой данных, а также выбором первых 20 строк:
SELECT s.store_id, SUM(s.product_units) AS product_amount
FROM marketing.sales AS s
GROUP BY (s.store_id)
ORDER BY product_amount DESC
LIMIT 20
SELECT без таблицы
Запрос на выделение года из метки времени:
SELECT CAST(EXTRACT(YEAR FROM TIMESTAMP '2001-02-16 20:38:40') AS INT)
OFFSET
Запрос 20 строк, начиная с десятой:
SELECT * from marketing.sales_snapshot OFFSET 9 FETCH NEXT 20 ROWS ONLY
Описание ключевого слова см. в секции Ключевое слово OFFSET.
ORDER BY, LIMIT и OFFSET
Запрос 20 строк, упорядоченных по значению id и выбираемых начиная с шестой строки результата:
SELECT * from marketing.sales_snapshot ORDER BY id LIMIT 20 OFFSET 9
Такое сочетание ключевых слов позволяет выбирать данные порциями с сохранением их порядка.
FOR SYSTEM_TIME AS OF DELTA_NUM
Запрос данных по состоянию на момент закрытия дельты с номером 9 из материализованного представления:
SELECT * FROM matview_db.sales_and_stores FOR SYSTEM_TIME AS OF DELTA_NUM 9
Описание ключевого слова см. в секции Ключевое слово FOR SYSTEM_TIME.
FOR SYSTEM_TIME AS OF CN
Запрос данных по состоянию на операцию 1744983131164721 из логической таблицы:
SELECT * FROM marketing.sales FOR SYSTEM_TIME AS OF CN 1744983131164721
FOR SYSTEM_TIME STARTED TS
Запрос записей, добавленных и измененных за период с 2023-04-17 10:00:00.123 по 2023-04-30 22:00:00.123 включительно:
SELECT * FROM marketing.sales FOR SYSTEM_TIME STARTED TS ('2023-04-17 10:00:00.123', '2023-04-30 22:00:00.123')
Запрос добавленных и удаленных записей с указанием периода в виде Unix-времени:
SELECT * FROM marketing.sales FOR SYSTEM_TIME STARTED TS (1681725600123000, 1682892000123000)
Запрос добавленных и удаленных записей с указанием периода в виде меток времени разного формата:
SELECT * FROM marketing.sales FOR SYSTEM_TIME STARTED TS ('2023-04-17 10:00:00.123', 1682892000123000)
Соединение таблиц из разных логических БД
Запрос с соединением данных логических таблиц из двух разных логических БД:
SELECT
st.id,
st.category,
s.product_code
FROM marketing.stores AS st
INNER JOIN marketing_new.sales AS s
ON st.id = s.store_id
О возможных типах соединений см. в секции Поддерживаемые типы соединений.
Соединение изменений по выбранным полям
Запрос изменений по трем полям за два месяца:
SELECT
transaction_id,
store_id,
store_region
FROM (
SELECT
sales.id AS transaction_id,
stores.id AS store_id,
stores.region AS store_region
FROM sales FOR SYSTEM_TIME AS OF '2023-11-14 20:00:00'
JOIN stores FOR SYSTEM_TIME AS OF '2023-11-14 20:00:00'
ON sales.store_id = stores.id
) t2
EXCEPT
SELECT
transaction_id,
store_id,
store_region
FROM (
SELECT
sales.id AS transaction_id,
stores.id AS store_id,
stores.region AS store_region
FROM sales FOR SYSTEM_TIME AS OF '2023-09-14 20:00:00'
JOIN stores FOR SYSTEM_TIME AS OF '2023-09-14 20:00:00'
ON sales.store_id = stores.id
) t1
Запрос изменений дельты из логического представления
Создание логического представления:
CREATE VIEW marketing.marketing_sales_join_stores AS SELECT * FROM marketing.sales as s JOIN marketing.stores as st ON st.id = s.store_id
Запрос записей логического представления, добавленных или измененных в дельте 10:
SELECT * FROM marketing.marketing_sales_join_stores FOR SYSTEM_TIME STARTED IN (10, 10)
Запрос данных из прокси-таблицы
SELECT p.type_code, SUM(p.amount) AS amount, p.currency_code
FROM marketing.payments_proxy AS p
GROUP BY p.type_code, p.currency_code
Запрос данных из standalone-таблицы
-- запрос данных из standalone-таблицы, на которую указывает внешняя readable-таблица payments_ext_read_adqm
SELECT p.agreement_id, p.code, SUM(p.amount) AS amount, p.currency_code
FROM marketing.payments_ext_read_adqm AS p
GROUP BY p.agreement_id, p.code, p.currency_code
Соединение standalone-таблицы и логической таблицы
-- запрос данных из логической таблицы clients и standalone-таблицы, на которую указывает
-- внешняя readable-таблица agreements_ext_read_adp
SELECT a.id, a.client_id, c.last_name, c.first_name, c.patronymic_name
FROM marketing.agreements_ext_read_adp AS a
LEFT JOIN marketing.clients FOR SYSTEM_TIME AS OF delta_num 9 AS c
ON a.client_id = c.id
Запрос данных из партиционированных таблиц
Запрос из партиционированной таблицы с условием:
SELECT * FROM marketing.sales_partitioned
WHERE id > 100
AND transaction_date BETWEEN '2023-01-01 00:00:00' AND '2023-01-17 23:59:59'
Запрос из партиционированной таблицы без условия:
SELECT * FROM marketing.sales_partitioned
ORDER BY transaction_date DESC
LIMIT 10
Запрос данных из соединения двух партиционированных таблиц с условием:
SELECT
st.id AS store_id,
st.region_code as store_region,
st.address AS store_address,
st.rent_agreement_id AS agreement_id,
r.number AS agreement_number,
r.closing_date AS agreement_closing_date
FROM marketing.stores_partitioned_by_regions AS st
JOIN marketing.rent_agreements_partitioned_by_regions AS r
ON st.rent_agreement_id = r.id
WHERE st.region_code IN (77, 177, 97, 197, 99, 199, 777, 78, 98, 178)
Запрос данных из партиции
SELECT * FROM marketing.sales_jan_2023
WHERE product_code <> 'ABC111' OR product_code IS NULL
Запрос данных, включая системные столбцы sys_from и sys_to
SELECT *, sys_from, sys_to FROM marketing.sales
На рисунке ниже показан пример ответа на запрос.
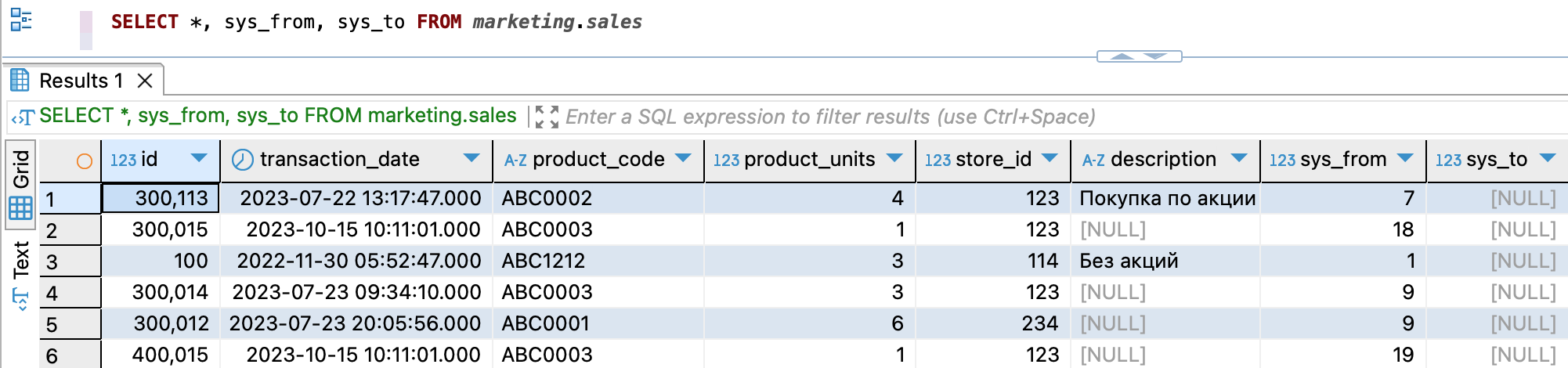
Ответ с системными столбцами sys_from и sys_to
Запрос данных с фильтром по системному столбцу sys_from
SELECT * FROM marketing.sales WHERE sys_from > 1745393948920192
На рисунке ниже показан пример ответа на запрос.
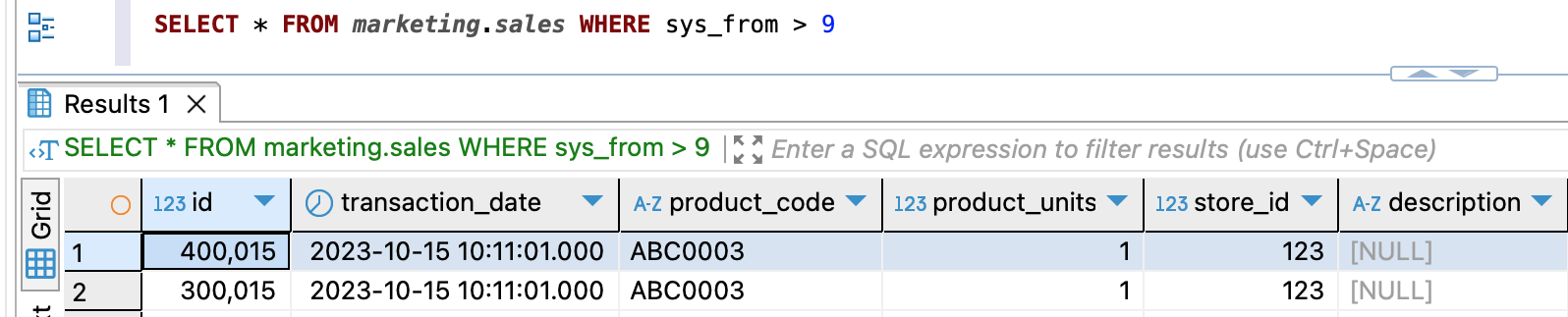
Ответ со строками, отфильтрованными по значению системного столбца sys_from
Запрос с именованными параметрами
Запрос с именованными параметрами в функции текстового поиска TO_TSQUERY и ключевых словах LIMIT и OFFSET:
SELECT * FROM marketing.sales
WHERE to_tsvector('russian', description) @@ to_tsquery('russian', :search_item)
ORDER BY transaction_date
LIMIT :limit_value
OFFSET :offset_value
DATASOURCE_TYPE = 'adp'
Пример полного cURL-запроса:
curl -X 'POST' \
'http://localhost:9090/api/v1/datamarts/marketing/query?format=json' \
-H 'x-request-id: 33e53112-9637-4622-be63-082ce49cf741' \
-H 'Content-Type: application/json' \
-d '{
"query": "SELECT * FROM marketing.sales WHERE to_tsvector('russian', description) @@ to_tsquery('russian', :search_item) ORDER BY transaction_date LIMIT :limit_value OFFSET :offset_value DATASOURCE_TYPE = 'adp'",
"queryId": "726449",
"params": [
{
"name": "search_item",
"value": "акция & (лето | зима)",
"type": "STRING"
},
{
"name": "limit_value",
"value": 20,
"type": "LONG"
},
{
"name": "offset_value",
"value": 40,
"type": "LONG"
}
]
}'
Запрос с индексированными параметрами
Запрос с индексированными параметрами в функции текстового поиска TO_TSQUERY и ключевых словах LIMIT и OFFSET:
SELECT * FROM marketing.sales
WHERE to_tsvector('russian', description) @@ to_tsquery('russian', ?)
ORDER BY transaction_date
LIMIT ?
OFFSET ?
DATASOURCE_TYPE = 'adp'
Пример cURL-запроса:
curl -X 'POST' \
'http://localhost:9090/api/v1/datamarts/marketing/query?format=json' \
-H 'x-request-id: 33e53112-9637-4622-be63-082ce49cf741' \
-H 'Content-Type: application/json' \
-d '{
"query": "SELECT * FROM marketing.sales WHERE to_tsvector('russian', description) @@ to_tsquery('russian', ?) ORDER BY transaction_date LIMIT ? OFFSET ? DATASOURCE_TYPE = 'adp'",
"queryId": "726449",
"params": [
{
"value": "акция & (лето | зима)",
"type": "STRING"
},
{
"value": 20,
"type": "LONG"
},
{
"value": 40,
"type": "LONG"
}
]
}'
Запрос с табличным параметром
Запрос с табличным параметром store_and_product_filter в JOIN-соединении:
SELECT s.* FROM marketing.sales s
JOIN @store_and_product_filter
ON s.store_id = @store_and_product_filter.store_id
AND s.product_code = @store_and_product_filter.product_code
WHERE s.transaction_date >= DATE_TRUNC(MONTH, TIMESTAMPADD(MONTH, -1, current_date))
AND s.transaction_date < DATE_TRUNC(MONTH, current_date)
DATASOURCE_TYPE = 'adp'
Здесь запрос для наглядности показан в человекочитаемом виде. В реальности запрос передается вместе с данными табличного параметра в бинарном формате (см. /query-upload).
Запросы к сущностям, версионируемым во внешней системе
Запросы к логическому представлению marketing.v5_sales, равнозначные друг другу:
-- имя сущности в формате Prostore
SELECT * FROM marketing.v5_sales;
-- имя сущности в формате Prostore (в выбранной логической БД)
USE marketing;
SELECT * FROM v5_sales;
-- имя сущности в формате внешней системы
SELECT * FROM marketing.5.0.sales;
-- имя сущности в формате внешней системы (в выбранной логической БД)
USE marketing;
SELECT * FROM 5.0.sales;
Запросы к логической таблице marketing.sales, равнозначные друг другу (при условии, что сущности marketing.v82_sales нет в логической БД):
-- имя сущности в формате Prostore
SELECT * FROM marketing.sales;
-- имя сущности в формате Prostore (в выбранной логической БД)
USE marketing;
SELECT * FROM sales;
-- имя сущности в формате внешней системы
SELECT * FROM marketing.82.0.sales;
-- имя сущности в формате внешней системы (в выбранной логической БД)
USE marketing;
SELECT * FROM 82.0.sales;